I. Introduction
A spectrometer is a sensing device for classifying various materials based on the interactions between electromagnetic waves and the material. Radiated electromagnetic waves can be absorbed or reflected by a material. Therefore, the spectrum of the reflected electromagnetic wave as a function wavelength can be considered a fingerprint of the material. Among various spectrometers, a visible-near-infrared (VIS-NIR) spectrometer is useful for analyzing materials and can be used to identify the constituents of food. VIS-NIR spectroscopy was first applied in agriculture by Norris to measure the moisture in grain [1]. Various spectrometers and pretreatment techniques have been developed for analyzing the constituents of various materials and foods [2–4]. Recently, food products containing genetically modified organisms (GMO) have been studied using NIR spectroscopy [5].
Industrial or laboratory VIS-NIR spectrometers have excellent performance. However, these spectrometers are not suitable for use in various locations such as in homes or offices because of their size and cost. Therefore, portable VISNIR spectrometers are being actively developed and validated [6].
In this paper, we classify eight food powders using a portable VIS-NIR spectrometer with three supervised classification methods that are generally used. Our experimental results demonstrate the potential for analyzing food ingredients using a portable VIS-NIR spectrometer.
The rest of the paper is organized as follows. In Section II, we introduce the VIS-NIR spectroscopy for the identification of food constituents and discuss the disadvantages of existing laboratory VIS-NIR spectrometers. The portable VIS-NIR spectrometer, food powders, and supervised classification algorithms used in the experiment are then explained. In Section III, we describe our machine learning process. We analyze the results of the three machine learning algorithms used and the effect of the training set size in Section IV. Finally, we conclude with a discussion of our results.
II. Materials and Methods
1. Portable VIS-NIR Spectrometer
We use a portable VIS-NIR spectrometer from Stratio Inc. (www.stratiotechnology.com) called LinkSquare. LinkSquare in Fig. 1 is a Silicon (Si)-based VIS-NIR spectrometer that is significantly more affordable than the NIR spectrometers typically found in the laboratory. This spectrometer has two light sources, white LED and BULB, and measures within the wavelength range of 450–1,000 nm [7]. Table 1 provides the detailed specifications of LinkSquare.
2. Food Powders and VIS-NIR Spectra
In this paper, we evaluate eight common food powders that are visually indistinguishable: salt, sugar, cream, flour, bean, corn, rice, and potato powder. Fig. 2 shows the eight food powders selected.
We measure the eight food powders using the portable VIS-NIR spectrometer. The process of spectral data acquisition as illustrated in Fig. 1, is conducted in a constant condition of ambient illumination and measuring angle. The spectral data obtained with each light source of the spectrometer are shown in Fig. 3.
III. Classification of Food Powders
1. Supervised Classification Methods
In this paper, we use three supervised classification methods for machine learning: support vector machine (SVM), k-nearest neighbors (kNN), and random forest (RF). SVM is one of the standard methods of classification and is most effective when the number of dimensions is the greater than the number of samples [8]. kNN utilizes a simple algorithm based on the distance between the training data and test data. It defines the nearby k training data as a neighbor and predicts the greatest number of labels among the k neighbors as the test label [9]. Proposed by Breiman, RF consists of several decision trees, and it is also described as ensemble learning [10]. RF uses the number of trees as an important hyperparameter. If the number of decision trees is small, the training speed will be fast but the accuracy will be low. Conversely, the larger the number of decision trees is, the higher the accuracy but the slower the training speed.
All machine learning methods are implemented in Python with the use of numpy, scipy, and scikit-learn [8].
2. Training and Validation Method
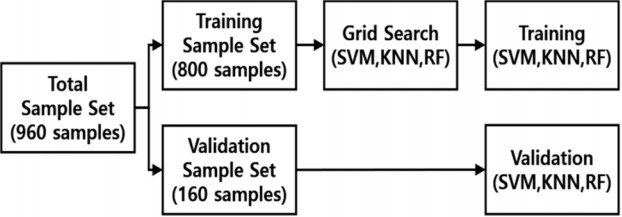
Fig. 4 shows the machine learning process in this experiment. We divide the total sample set (960 samples) into a training sample set (800 samples) and a validation sample set (160 samples). We then design the machine learning models with the training sample set using the three supervised classification methods. We demonstrate the performance of each model with the validation sample set.
3. Optimal Parameter Selection
We use the grid-search function to find the optimal parameters for the three machine learning methods. We set the suitable parameter ranges for SVM, kNN, and RF and then, find the optimal parameters for machine learning through repetitive experiments using the grid-search function. The detailed parameters for the experiment are given in Table 2.
SVM can use a kernel function, and thus we consider the linear and radial basis function (RBF) kernel. The RBF kernel has a parameter gamma, which defines how much influence a single training example has. Parameter C is called the penalty parameter, which controls the tradeoff between margin maximization and error minimization. The performance of kNN varies on the basis of parameter k, called n_neighbors in scikit-learn. In general, a larger k suppresses the effects of noise, but makes the classification boundaries smoother. RF models with different parameter n_estimators which are the number of trees in the forest are evaluated.
IV. Classification Results
1. Results and Confusion Matrix
We verify the three machine learning models using the validation sample set. We evaluate the performance of the classification in terms of accuracy, recall, precision and F1 score [11].
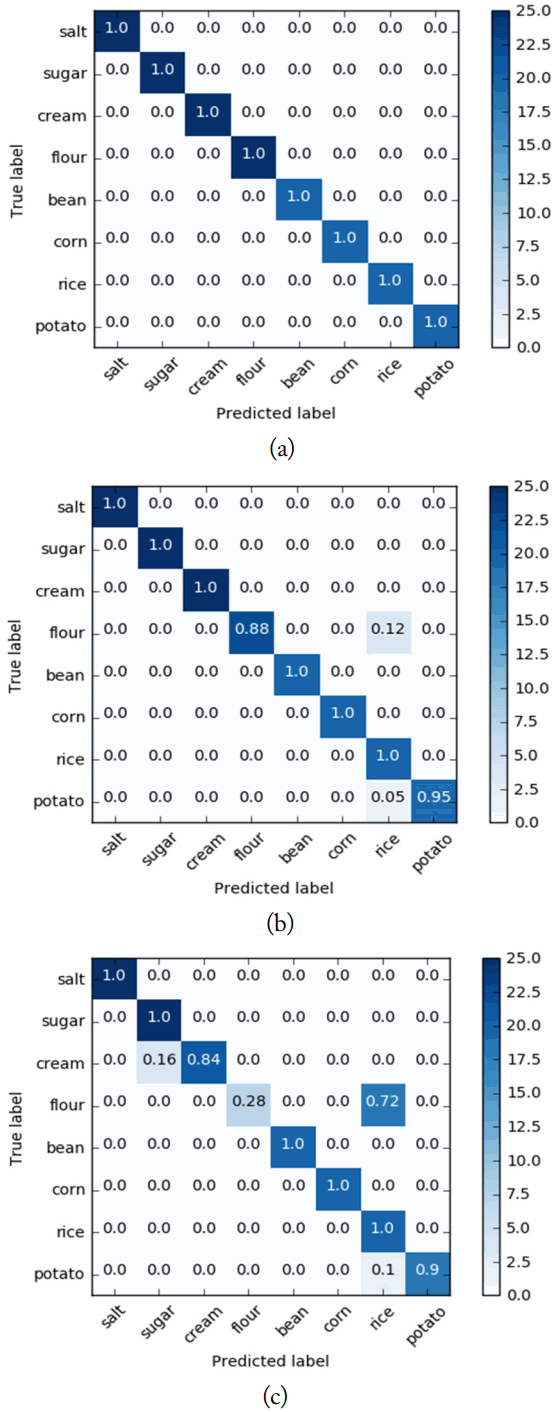
Table 3 shows the results of the experiment. We observe that the three machine learning methods almost successfully classify all eight food powders. RF, kNN, and SVM achieve an accuracy of 87%, 98%, and 100%, respectively. SVM shows high performance because it transforms the non-linear spectral data into the maximum-margin hyperplane.
We further investigate the confusion matrices for the three machine learning methods as shown in Fig. 5. Although kNN and RF have high accuracy, they fail to accurately classify some food powders. In particular, 72% of the flour powder is misidentified as rice powder.
2. Size of the Training Sample Set
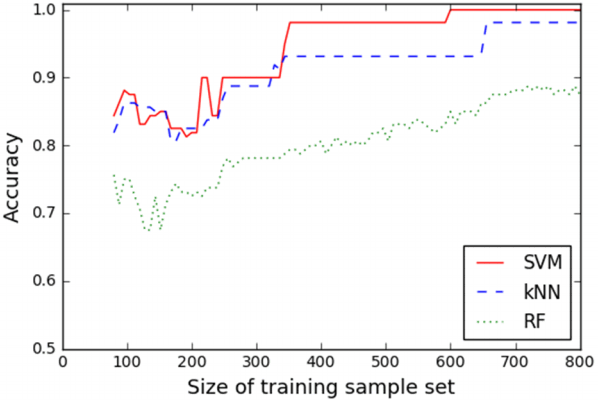
Next, we investigate the effect of the training sample set size for efficient machine learning training. We test iteratively by changing the size of the training sample set. Fig. 6 shows the effect of the training sample set size on the classification performance. The classification accuracy enhances as the training sample set size increases and plateaus after a certain size. We obtain as many training samples as we obtain to guarantee the classification performance of SVM, but RF requires more training samples than what we have obtained.
V. Conclusion
We present the possibility of converging VIS-NIR spectroscopy and machine learning in this paper. Eight food powders are classified using a portable VIS-NIR spectrometer with three supervised classification methods. The successful classification results for the eight food powders show the feasibility of using a portable VIS-NIR spectrometer for analyzing food ingredients. As portable VIS-NIR devices develop further, they can be used for more varied purposes.